UTF-8 ist eine Zeichenkodierung, die nahezu alle Schriftzeichen der Welt in digitalen Texten darstellen kann. Sie wurde im Rahmen des Unicode-Standards entwickelt und kann alle 1.112.064 gültigen Unicode-Codepunkte mit ein bis vier Bytes pro Zeichen kodieren. Stand 2025 sind mehr als 98 % aller Webseiten in UTF-8 kodiert. Dieser Blog-Artikel gibt eine Einführung in UTF-8 inklusive Abgrenzung zu andern Textkodierungen sowie ein paar praktische Tipps zum Abschluß.
Begriffsdefinition
UTF-8 (Kurzform für 8-Bit Unicode Transformation Format) ist eine Zeichenkodierung, die Unicode-Zeichen in eine Folge von ein bis vier Bytes übersetzt. Unicode selbst ist kein Kodierungsformat, sondern ein Zeichensatzstandard, der jedem Zeichen eine eindeutige Nummer (genannt Codepoint) zuweist. UTF-8 ist lediglich eine Möglichkeit, diese Codepoints technisch darzustellen.
Ein Blick zurück
Die Wurzeln von UTF-8 liegen in den Bestrebungen der späten 1980er und frühen 1990er Jahre, einen universellen Zeichensatz für alle Sprachen zu entwickeln. 1989 begann die International Organization for Standardization (ISO) mit ISO 10646 einen 32-Bit-Zeichensatz zu standardisieren. Ein früher Entwurf enthielt eine Kodierung namens UTF-1, die jedoch in der Praxis zu langsam war und vor allem keine klare Trennung zwischen ASCII- und Nicht-ASCII-Bytes erlaubte. So konnten bestimmte Bytefolgen von UTF-1 mit Werten im Bereich 0x21–0x7E – etwa 0x2F (der Schrägstrich /) – in ASCII-Programmen fälschlich als normale Zeichen (z.B. Trennzeichen für Verzeichnise) interpretiert werden. Dieses Kompatibilitätsproblem machte deutlich, dass eine bessere Lösung nötig war.
Im Juli 1992 suchte das Komitee X/Open (heute: The Open Group) nach einer leistungsfähigeren Unicode-Kodierung. Dave Prosser von Unix System Laboratories schlug eine Variante namens FSS-UTF (File System Safe UCS Transformation Format) vor, bei der die 7-Bit-ASCII-Zeichen unverändert blieben und Multibyte-Sequenzen nur Bytes größer oder gleich 0x80 verwendeten. Dieser Vorschlag wurde im August 1992 weitergereicht, u.a. an IBM. Ken Thompson von den Bell Laboratories (Plan-9-Entwicklungsteam) modifizierte den Ansatz anschließend entscheidend: Er führte ein selbstsynchronisierendes Byte-Format ein, bei dem die Grenzen zwischen Zeichen eindeutig erkennbar sind. Gemeinsam mit Rob Pike entwarf er am 2. September 1992 bei einem Abendessen in New Jersey das grundlegende Design von UTF-8 auf einer Serviette (ob das wirklich stimmt, weiß ich nicht, klingt aber gut). In den darauffolgenden Tagen implementierten Thompson und Pike die Kodierung im Betriebssystem Plan 9 und meldeten ihren Erfolg zurück an X/Open, das den Vorschlag annahm.
Bereits im Januar 1993 wurde UTF-8 auf der USENIX-Konferenz in San Diego offiziell präsentiert. Kurz darauf floss UTF-8 in die Unicode- und ISO-10646-Standards ein und etablierte sich in den folgenden Jahren zunächst vor allem in Unix-Systemen als bevorzugte Unicode-Kodierung. Die Internet Engineering Task Force (IETF) empfahl UTF-8 ab 1998 als Standardzeichensatz für Internet-Protokolle (RFC 2277) anstelle älterer Ein-Byte-Codes wie Latin-1. Obwohl Betriebssysteme wie Windows in den 1990ern zunächst auf UCS-2/UTF-16 setzten, setzte sich UTF-8 durch seine praktischen Vorteile langfristig als universeller Standard durch.
Diese praktischen Vorteile lassen sich wie folgt zusammenfassen:
-
Universelle Zeichenabdeckung: UTF-8 kann sämtliche Unicode-Zeichen abbilden – vom einfachen lateinischen Buchstaben über Umlaute, arabische und kyrillische Zeichen bis hin zu chinesischen Schriftzeichen, historischen Alphabeten und modernen Emojis. Dadurch ist UTF-8 für mehrsprachige Inhalte und globale Anwendungen ideal geeignet. In einem einzigen Dokument lassen sich problemlos verschiedene Schriftsysteme kombinieren – ohne Zeichenverluste oder Darstellungsfehler.
-
ASCII-Kompatibilität: Ein wesentliches Merkmal von UTF-8 ist seine vollständige Kompatibilität mit ASCII. Alle Zeichen im Bereich
U+0000bisU+007Fwerden byteidentisch gespeichert – das bedeutet: Bestehende ASCII-Dateien sind automatisch auch gültige UTF-8-Dateien. Diese Eigenschaft ermöglicht eine nahtlose Integration in bestehende Systeme und erleichtert die schrittweise Umstellung älterer Software auf Unicode, ohne dass sofort alle Komponenten angepasst werden müssen. -
Effiziente Speicher- und Bandbreitennutzung: UTF-8 verwendet eine variable Byte-Länge, wodurch der Speicherbedarf an den tatsächlichen Zeicheninhalt angepasst wird. Häufige Zeichen (wie Buchstaben, Ziffern und Satzzeichen) benötigen nur ein einziges Byte, komplexere Zeichen zwei bis vier Bytes. Dadurch ist UTF-8 bei westlich geprägten Texten häufig platzsparender als UTF-16 oder UTF-32 und eignet sich hervorragend für die Übertragung von Text über Netzwerke oder für die Speicherung großer Datenmengen.
-
Robust und fehlertolerant: Durch seine selbstsynchronisierende Struktur lassen sich UTF-8-Zeichen zuverlässig erkennen – auch wenn man an einer beliebigen Stelle in einen Textstrom springt. Fehlerhafte oder unvollständige Byte-Sequenzen lassen sich leicht identifizieren, was die Verarbeitung sicherer macht. Diese Eigenschaft ist besonders wertvoll beim Parsen, Durchsuchen oder Wiederherstellen von Textdateien.
-
Breite Unterstützung in Software und Protokollen: UTF-8 wird von praktisch allen modernen Betriebssystemen, Programmiersprachen, Texteditoren und Netzwerkprotokollen vollständig unterstützt. Besonders im Web ist UTF-8 der dominierende Zeichensatz – nahezu alle Webseiten nutzen heute diese Kodierung. Diese breite Akzeptanz macht UTF-8 zur sicheren Wahl für den plattformübergreifenden Austausch von Textinhalten.
Technischer Aufbau
UTF-8 ist eine variable Mehrbyte-Kodierung. Das bedeutet, je nach Unicode-Codepoint wird ein Zeichen mit unterschiedlich vielen Bytes dargestellt. Die Länge einer UTF-8-Sequenz lässt sich am ersten Byte erkennen:
-
Für die Unicode-Zeichen
U+0000bisU+007F(die dem ASCII-Bereich entsprechen) verwendet UTF-8 genau 1 Byte. Dieses beginnt mit der Bitfolge0xxxxxxx(eine führende 0), was die Werte0x00–0x7Fabdeckt.Beispiel:
Das Zeichen A (
U+0041) hat in UTF-8 die Bytefolge0x41(ein einzelnes Byte mit dem Dezimalwert65) – identisch zum ASCII-Code. -
Die Unicode-Zeichen
U+0080bisU+07FFwerden mit 2 Bytes kodiert. Das erste Byte beginnt mit dem Bitmuster110xxxxxund das zweite Byte mit10xxxxxx. Damit lassen sich 11-Bit-Werte darstellen (die restlichen Bits des ersten Bytes geben zusammen mit den 6 Bits des zweiten Bytes den Codepoint).Beispiel:
Der Buchstabe Ä (
U+00C4) liegt in diesem Bereich und wird in UTF-8 als0xC3 0x84kodiert. -
Die Unicode-Zeichen
U+0800bisU+FFFF(also der Rest der Basic Multilingual Plane (BMP) außer ASCII) werden mit 3 Bytes kodiert. Die Byte-Sequenz hat das Format1110xxxx 10xxxxxx 10xxxxxx. Hierdurch lassen sich 16-Bit-Werte abbilden, was alle BMP-Zeichen (z.B. €, 漢 oder أ) umfasst.Beispiel:
Das Euro-Zeichen € (
U+20AC) wird in UTF-8 als0xE2 0x82 0xACkodiert. Ebenso benötigt ein chinesisches Zeichen wie 你 (U+4F60) drei Bytes:0xE4 0xBD 0xA0. -
Die Unicode-Zeichen
U+10000bisU+10FFFF(das sind die Zeichen außerhalb der BMP, z.B. historische Schriftzeichen, seltene Schriftarten und Emojis) werden mit 4 Bytes kodiert. Die Struktur ist11110xxx 10xxxxxx 10xxxxxx 10xxxxxx. Damit können bis zu 21 Bit große Codepunkte kodiert werden. Der höchsten Unicode-Wert wäreU+10FFFF(entspricht dezimal 1.114.111).Beispiel:
Das Emoji 😊 (
U+1F60A) wird in UTF-8 als0xF0 0x9F 0x98 0x8Akodiert.
Jedes UTF-8-Byte lässt an seinen obersten Bits erkennen, ob es ein Startbyte eines neuen Zeichens oder ein Fortsetzungsbyte ist. Startbytes von Mehrbyte-Sequenzen tragen zwei oder mehr führende 1-Bits (z.B. 110xxxxx für 2-Byte-Sequenzen, 1110xxxx für 3 Bytes, 11110xxx für 4 Bytes), während Fortsetzungsbytes stets mit 10 beginnen. Ein einzelnes ASCII/UTF-8-Byte beginnt dagegen mit 0 und signalisiert so ein 1-Byte-Zeichen.
Durch dieses Präfix-System ist UTF-8 ein selbstsynchronisierendes Kodierungsformat: Wenn man an einer beliebigen Byteposition in einen UTF-8-Strom “hineinspringt”, kann man spätestens nach ein bis zwei Byte erkennen, wo die nächste gültige Zeichenbegrenzung liegt. Ungültige Fortsetzungsbytes (d.h. Bytes, die mit 10 beginnen, aber keinem vorherigen Startbyte zugeordnet werden können) lassen sich leicht erkennen. Diese Eigenschaft verhindert die Verwechslung von Teilsequenzen mit echten Zeichen und erleichtert z.B. das Durchsuchen von UTF-8-Text oder die Wiederherstellung synchroner Lesepositionen.
Ohne oder mit BOM
Eine oft diskutierte Variante von UTF-8 betrifft das sogenannte Byte Order Mark (BOM). Ein BOM ist ein spezielles unsichtbares Zeichen (U+FEFF), das am Beginn einer Textdatei stehen kann, um die Kodierung der Datei zu kennzeichnen. In UTF-16 und UTF-32 (siehe auch weiter unten) ist ein BOM wichtig, um die Byte-Reihenfolge (Little Endian vs. Big Endian) zu erkennen, da diese Formate anfällig für Byte-Reihenfolgeprobleme sind. Bei UTF-8 hingegen gibt es keine Byte-Reihenfolge-Problematik, da die Kodierung byteorientiert ist – daher ist ein BOM bei UTF-8 optional.
Einige Programme (vor allem unter Windows) fügen trotzdem ein BOM (also die Bytefolge 0xEF 0xBB 0xBF) am Anfang von UTF-8-Dateien ein, um dem Leser die Kodierung anzuzeigen. Das BOM ist für UTF-8 jedoch nicht erforderlich und in vielen Fällen sogar unerwünscht: Es kann z.B. bei Unix-Werkzeugen oder auf Webseiten als “Geisterzeichen” am Textanfang erscheinen, wenn ed nicht korrekt erkannt wird. Die allgemeine Empfehlung lautet daher, UTF-8 ohne BOM zu verwenden, sofern kein spezieller Grund für dessen Einsatz vorliegt. Moderne Software erkennt UTF-8 in der Regel auch ohne BOM anhand von Heuristiken oder Vorgaben (etwa der Content-Type-Deklaration im Web oder dem encoding-Attribut in XML).
Abgrenzung zu UTF-16 und UTF-32
Ursprünglich sollte Unicode alle Zeichen in 16 Bit unterbringen – das entsprach 65.536 möglichen Codepoints (U+0000 bis U+FFFF), ausreichend für viele Schriftsysteme. Dieses Format wurde als UCS-2 bekannt und war in den 1990er Jahren weit verbreitet, u.a. in Windows NT und Java.
Doch schon bald zeigte sich: Die Zahl der weltweit benötigten Zeichen (z. B. für chinesische, historische oder technische Schriftzeichen) sprengte diese Grenze. Unicode wurde deshalb ab Version 2.0 (1996) auf mehr als 1 Million Codepoints erweitert (bis U+10FFFF).
Damit war UCS-2 zu klein geworden – es entstand die Notwendigkeit für eine erweiterte Kodierung, die sowohl mit der bisherigen Infrastruktur kompatibel war als auch zusätzliche Zeichen abbilden konnte.
Also wurde UTF-16 als Lösung eingeführt. Es erweitert das frühere UCS-2, indem es die Darstellung höherer Codepoints über sogenannte Surrogatpaare ermöglicht. Damit konnten vorhandene 16-Bit-basierte Systeme (wie Windows, Java) Unicode weiterhin nutzen – ohne auf ein komplett neues Kodierungsmodell umsteigen zu müssen.
Zusammengefasst:
-
UTF-16 ist entweder zwei Bytes oder vier Bytes groß.
-
Zeichen im Bereich
U+0000bisU+FFFF(Basic Multilingual Plane, BMP) werden mit einem 16-Bit-Wert gespeichert. -
Zeichen oberhalb von
U+FFFF(z. B. Emojis, historische Schriftzeichen) werden mit zwei 16-Bit-Werten kodiert – einem High Surrogate (U+D800bisU+DBFF) und einem Low Surrogate (U+DC00bisU+DFFF). -
Beispiel: Das Emoji 😊 (
U+1F60A) wird in UTF-16 als0xD83D 0xDE0Akodiert.
Die Reihenfolge der Bytes ist jedoch plattformabhängig, deshalb gibt es bei UTF-16 die Unterscheidung zwischen Little Endian (LE) und Big Endian (BE) sowie das Byte Order Mark (BOM) zur Kennzeichnung.
Später (sogar nach Veröffentlichung von UTF-8) kam auch noch UTF-32 hinzu. Es verfolgt einen radikal einfacheren Ansatz: Jedes Unicode-Zeichen wird exakt in 32 Bit (vier Bytes) gespeichert. Damit entfällt jegliche Umrechnung oder Sonderbehandlung – aber auf Kosten des Speicherplatzes.
Zusammengefasst:
-
Jedes Unicode-Zeichen wird in UTF-32 als ein einziger 32-Bit-Wert (vier Bytes) gespeichert.
-
Keine Surrogatpaare, keine variable Länge.
-
Beispiel: Das Emoji 😊 (
U+1F60A) wird als0x00 0x01 0xF6 0x0Agespeichert.
UTF-32 ist sehr einfach, aber ineffizient: Auch ein einfaches A (U+0041) belegt vier Bytes. Auch bei UTF-32 ist die Reihenfolge der Bytes plattformabhängig und ein BOM ist ebenfalls notwendig.
Im Unterschied zu UTF-16 und UTF-32 hat UTF-8 ein variable Länge (ist also platzsparender), benötigt kein BOM und ist ASCII-kompatibel.
Abgrenzung zu ISO 8859/ANSI
In den 1960er Jahren wurde ASCII als 7-Bit-Code (128 Zeichen) eingeführt, zunächst ausreichend für die englische Sprache (schon damals frei nach dem Motto “America First”). Für andere Sprachen galt das aber nicht – es fehlten zahlreiche Sonderzeichen wie z.B. ä, é, ñ, ß, € usw.
Da viele Systeme ohnehin 8-Bit-Bytes nutzten, lag es nahe, das achte Bit für 128 zusätzliche Zeichen (128–255) zu verwenden. So entstanden verschiedene 8-Bit-Zeichenkodierungen, meist auf ASCII basierend, aber mit einem sprachspezifischem Zusatzbereich. Ab Mitte der 80er Jahre wurden diese Kodierungen von der ISO unter ISO 8859 systematisch standardisiert.
Beispiele:
| ISO-Code | Sprache / Region | Beispielzeichen |
|---|---|---|
| ISO 8859-1 | Westeuropa (Latin-1) | ä, ö, ñ, ø, ß |
| ISO 8859-2 | Mitteleuropa (Latin-2) | č, ž, ś |
| ISO 8859-5 | Kyrillisch | Ж, Я, Ю |
| ISO 8859-6 | Arabisch | ا, ب, ت |
| ISO 8859-15 | Latin-1 + € | wie 8859-1 + Eurozeichen |
Microsoft hatte zu dieser Zeit mit offenen Standards nicht viel am Hut und definierte unter dem Begrfiff ANSI-Codepages eigene Varianten.
Beispiele:
| Codepage | Beschreibung | Bemerkung |
|---|---|---|
| Windows-1252 | Westeuropa | ähnlich ISO 8859-1 mit typografischen Zeichen (z. B. Gänsefüßchen) |
| Windows-1251 | Kyrillisch | abweichend von ISO 8859-5 |
| Windows-1250 | Mitteleuropa | für Sprachen wie Polnisch, Tschechisch |
ANSI ist kein klar definierter Standard, sondern eine umgangssprachliche Bezeichnung für die lokalen 8-Bit-Codepages unter Windows. Die Kodierungen wurden nie von ANSI (dem US-Standardisierungsinstitut) offiziell verabschiedet. Microsoft nannte sie nur so, weil man sich an den ANSI-C-Zeichensatz anlehnte.
Wie auch immer, allen 8-Bit-Zeichenkodierungen ist gemeinsam, dass das gleiche Byte oberhalb der ASII-Bereichs unterschiedliche Zeichen darstellen kann. Je nach Sprache wird dann entweder das richtige Zeichen oder Murks angezeigt. Auch ist beim Öffnen einer Textdatei nicht bekannt, welche Zeichenkodierung beim Speichern genutzt wurde. Und das man mit insgesamt 265 möglichen Zeichen manche Sprachen (z.B. Chinesisch oder Japanisch) gar nicht abbilden kann, sollte auch klar sein.
Im Unterschied zu ISO 8859/ANSI kann UTF-8 alle Sprachen gleichzeitig kodieren.
UTF-8 in der Praxis
Alles schön und gut, aber woher weiß ich denn, ob meine Textdatei UTF-8 kodiert ist oder nicht? Und wenn nicht, was mach ich dann?
Wie prüfe ich eine Textdatei auf UTF-8?
Das geht unter Windows mit Bordmitteln:
-
Öffne Deine Textdatei mit der Anwendung Editor (auf Englisch: Notepad), das ist der Standard-Texteditor unter Windows 11 und 10.
-
Unten rechts in der Statuszeile wird die aktuelle Zeichenkodierung angezeigt.
Windows-Editor
Wie konvertiere ich eine Textdatei nach UTF-8?
Auch hier hilft wieder der Standard-Texteditor unter Windows:
-
Öffne Deine Textdatei mit der Anwendung Editor.
-
Wähle im Menü
Dateiden BefehlSpeichern unter. -
Ein Dialogfenster öffnet sich. Dort ändere den Wert im Auswahlfeld
CodierungaufUTF-8und drücke auf Speichern.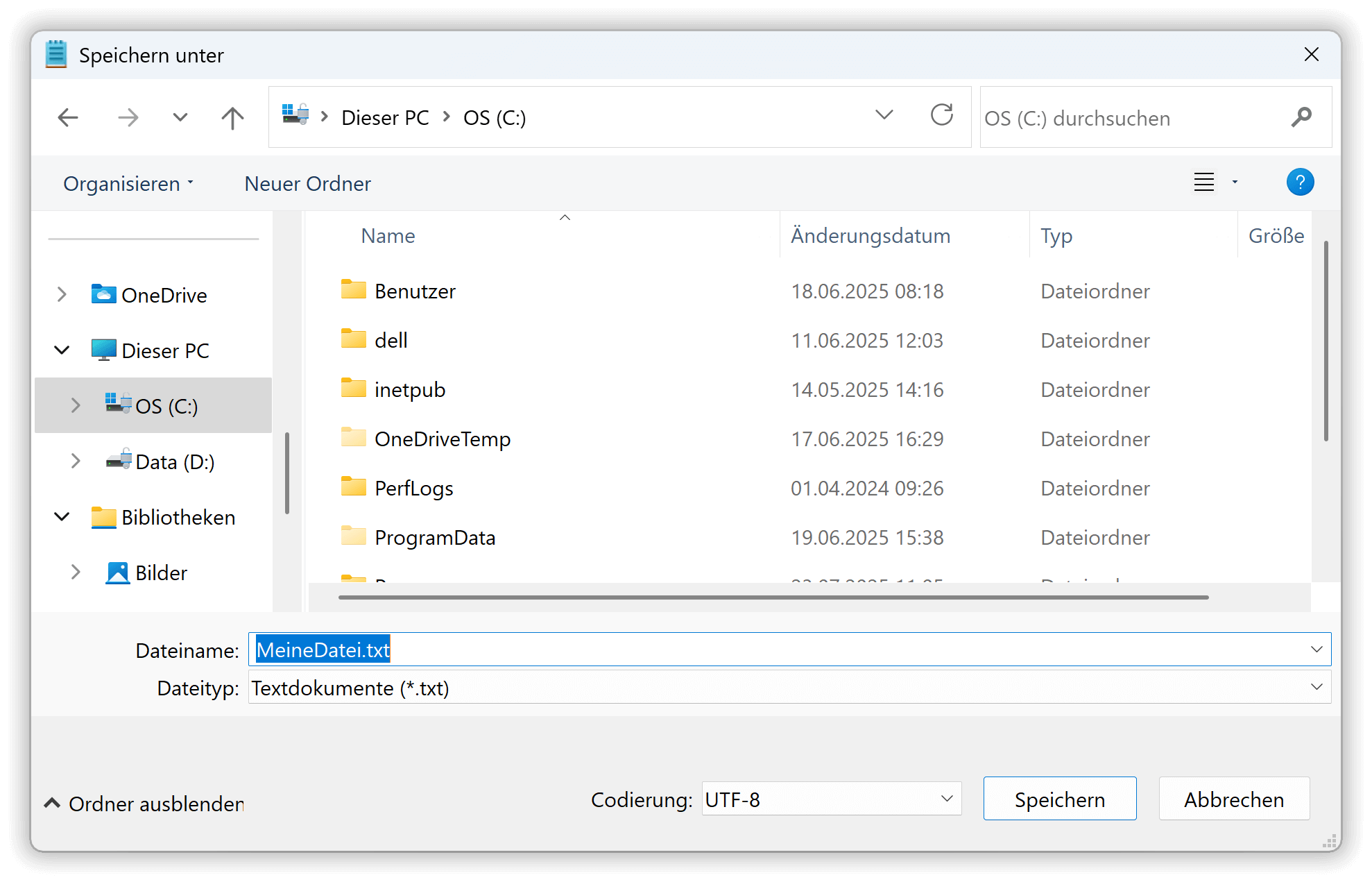
Speichern unter im Windows-Editor
Und mit Excel?
Möchtest Du in Excel eine Tabelle als CSV-Datei speichern, dann achte auf die Auswahl CSV UTF-8 (durch Trennzeichen getrennt):
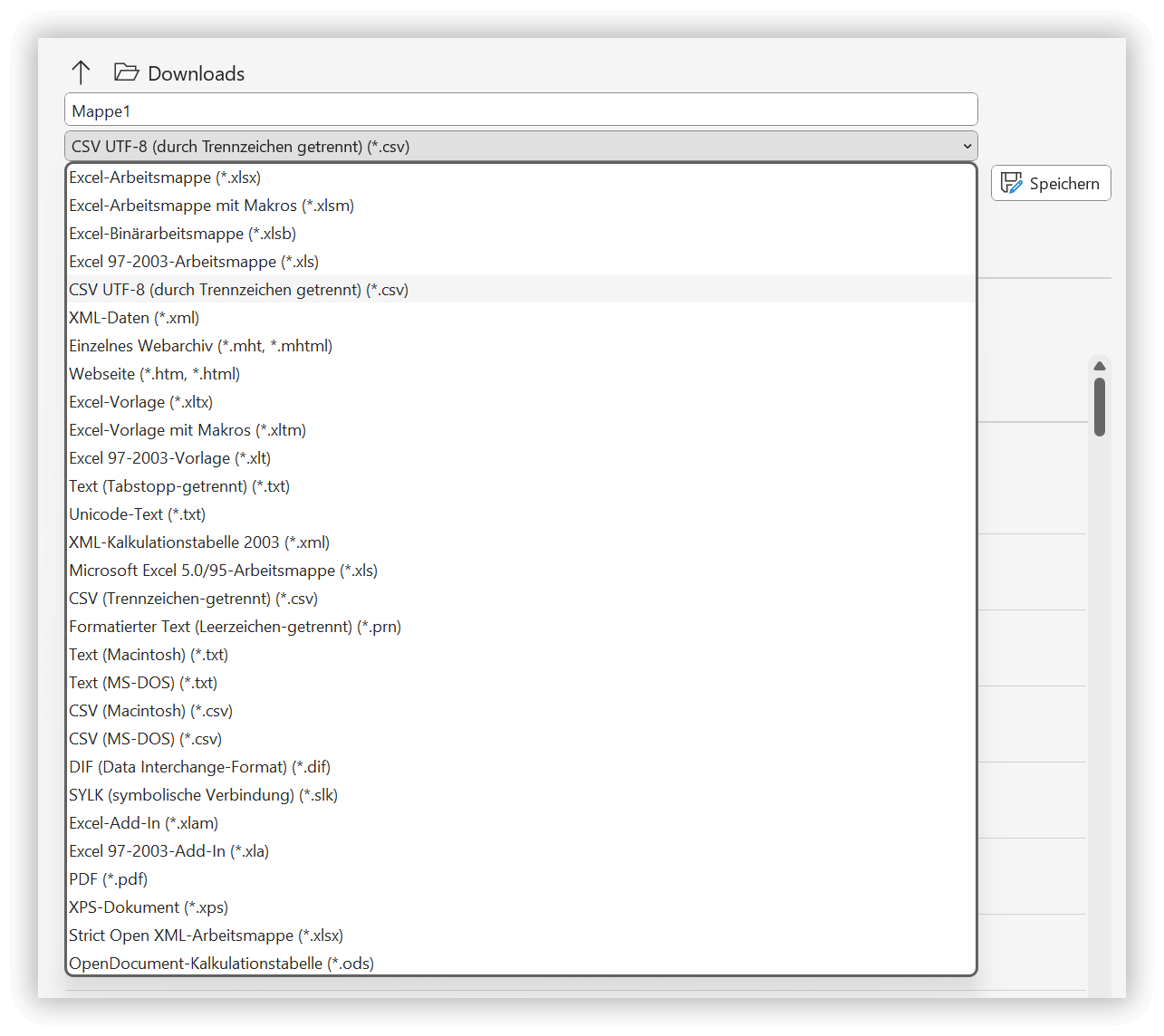
Speichern unter in Excel
Und via PowerShell?
Wer tausende von Textdateien konvertieren möchte, der kann das mit PowerShell automatisieren. Die grundlegende Befehlsfolge lautet:
Get-Content -Path AlteDatei.txt | Set-Content -Path NeueDatei.txt -Encoding UTF8
Dadurch entsteht NeueDatei.txt im UTF-8-Format.